It is very hard to find the right selectors to parse html code in php.
Now i have found the ultimate solution!
$fake_user_agent = "Mozilla/5.0 (X11; Linux i686) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.47 Safari/536.11";
ini_set('user_agent', $fake_user_agent);
libxml_use_internal_errors(true);
$dom = new DomDocument;
$dom->loadHTMLFile("https://socialblade.com/youtube/channel/UCJETl_inEdp0XXXXXXXXXQ");
$xpath = new DomXPath($dom);
$nodes = $xpath->query("//*[@id=\"YouTubeUserTopInfoBlock\"]/div[3]/span[2] | //*[@id=\"YouTubeUserTopInfoBlock\"]/div[4]/span[2]");
header("Content-type: text/plain");
foreach ($nodes as $i => $node) {
echo "Node($i): ", $node->nodeValue, "\n";
} With this code you are able to fake the user agent and bypass the socialblade filter. You can also easily change the xpath code to parse the html code in php.
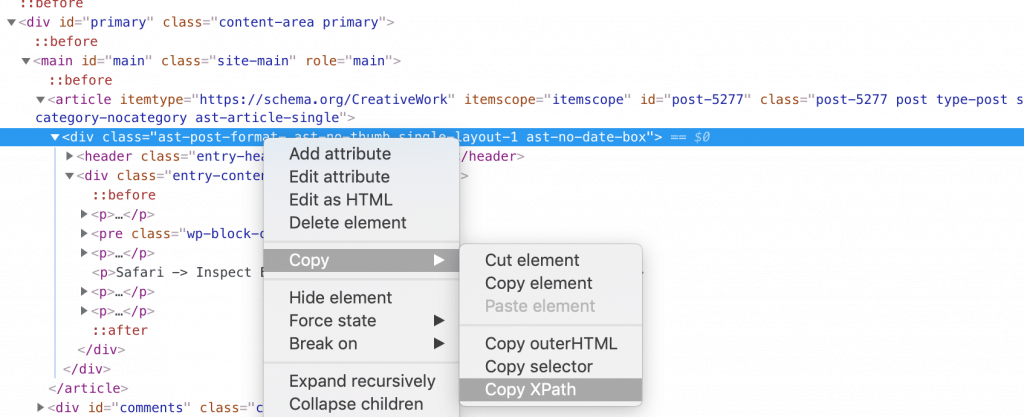
Safari -> Inspect Element -> Right Click -> Copy -> Copy xpath
And youre done! Its such easy. Just change the URL and xpath code and everything works fine.
I spent so much hours on finding the right selectors and the correct paths to the data i want and now it is just working within 30 seconds.
